|
|
|
Mayank Mishra
Tanmay Sarkar
Tanupriya Choudhury
|
|
Devanagari is a Northern Brahmic script related to many other South Asian scripts, including Gujarati, Bengali, and Gurmukhi, and, more distantly, to a number of South-East Asian scripts including Thai, Balinese, and Baybayin. More than 100 languages spoken in India and Nepal, including Sanskrit, Hindi, Nepali, Marathi, Bhojpuri, Maithili, etc., are written in the Devanagari script. However, advancements in building an Optical Character Recognition (OCR) for the Devanagari script have been limited compared to other Latin scripts. The recent advances in deep learning have opened opportunities to create an efficient character recognition system for the Devanagari script. In this project, we have exploited the strength of a deep neural network with ResNet architecture. Our ResNet holds eighty-five convolution layers and records an accuracy higher than the previous works on the Devanagari Handwritten Character Dataset (DHCD). |
|
There are several challenges to building a comprehensive character recognition for the Devanagari script.
|
|
We have used the Devanagari Handwritten Character Dataset (DHCD) to train and test our image classification model. This dataset was published in Deep Learning Based Large Scale Handwritten Devanagari Character Recognition and has been used as a standard dataset for Devanagari character recognition. The dataset consists of 78,200 images in the training set and 13,800 images in the testing set. Researchers scanned hundreds of handwritten documents of different writers and cropped each character manually. Each grayscale image is 32x32 pixels in dimension with white characters displayed on dark background. |

|
ResNet has opened up the possibilities to train deep neural networks without compromising with the accuracy. We have exploited the power of a deep neural network by implementing a ResNet architecture with eighty-five convolution layers.
|
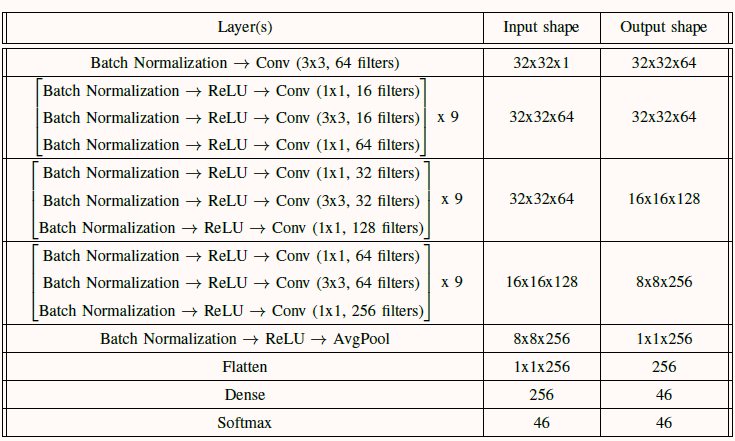
|
The model trains on the training set for 80 epochs. The stochastic gradient descent algorithm is used for optimization. The initial learning is set as 1 and the momentum as 0.9. Over the course of training, a linear learning rate decay is applied. Data augmentation is performed on all the images in the batch that undergoes training. Categorical crossentropy is set as the loss function, and the performance of the model is evaluated using the accuracy metric.
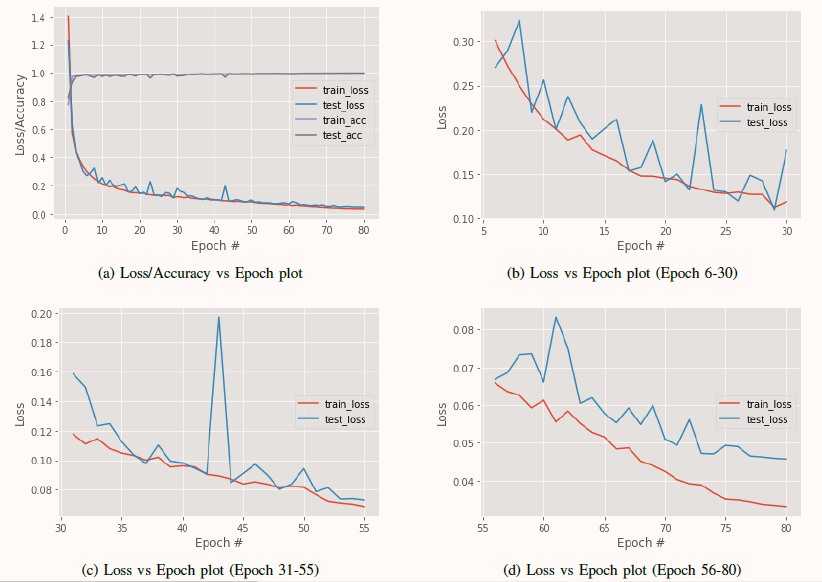
99.72 percent accuracy is obtained on the testing set. This is the highest ever accuracy recorded on the Devanagari Handwritten Character Dataset*. Figure 3 illustrates the performance of the model at various times of the training. A gradual decline in the loss is seen between epoch 6-55. Even after the point when the testing loss and the training loss start to diverge, the difference between the two remains constantly small. This result indicates that our overfitting is controlled even after training a deep neural network. We witness a plateau in learning close to epoch 80 and terminate the training. Figure 4 shows the successful recognition of a few sample images by the trained model.
*To the best of our knowledge |

|
The dataset used can be found here. |
|
Webpage last updated: June, 2021 |